AMICO: Documentation / Sample Scenarios
The proposed framework has been applied to and tested in different applications, several of which we describe in this section. The adaptable communication model and tools that we developed enable us to combine many components by simply reconfiguring the system. We start with straight-forward examples, which illustrate the use of off-the-shelf sensor modules for building interactive multimedia applications. We then describe a more complex example where the communicator is used in a complex multi-user and multi-sensory environment.
Camera-Based Playback Control
In this prototype, we have evaluated how camera based face detection, and other real-time computer vision techniques, can be used to control the playback of multimedia content. The basic scenario is that the system starts a playback when there is at least one person looking at the screen, it pauses playback when there is no one there, and continues again when someone else appears.
For the face detection component we have used OpenCV, an open source computer vision library. The data from the face detector, i.e. coordinates of detected faces, are transformed by the communicator transformations into variables that control the ScriptingApplet to influence the playback of multimedia content in players such as RealPlayer and Windows Media Player.

Basic configuration of components, and data flow in our camera-based playback control example.
In a similar way we also enabled that parts of the screen, such as background color, can be changed based on the number of the detected faces. The face-detecting sensing module can also recognize other object profiles, such as frontal face, profile, upper body, lower body, whole body, and it can be configured with the minimum size of an object. Minimal size of an object is an important parameter if we want to detect people or objects within a limited distance. The following figure shows illustrates derivation of variables from face-detection to playback control parameters.
|
|
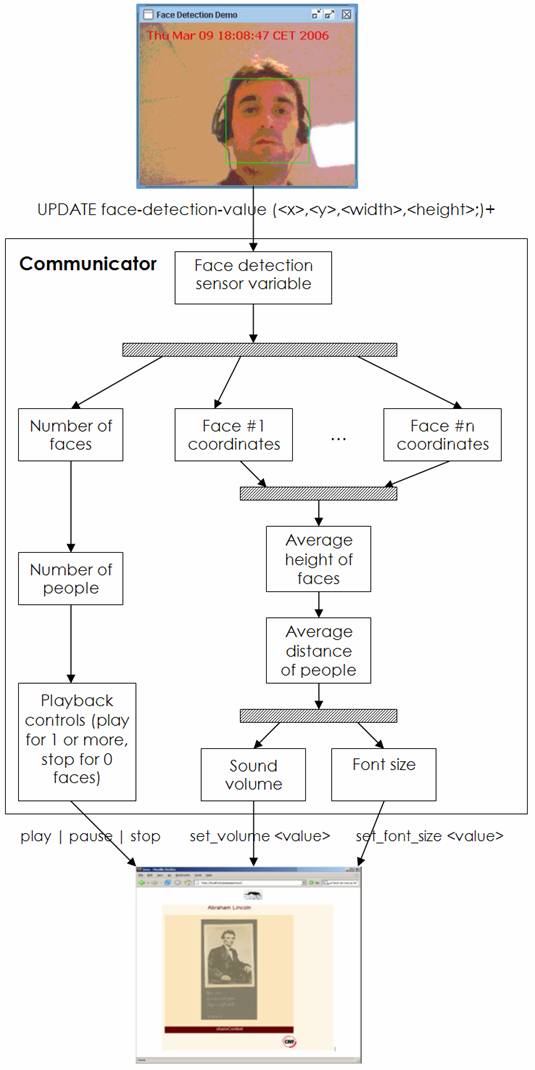
Derivation of variables in a camera based control of multimedia playback.
We also used other external sensing modules that can process camera input, such as EyesWeb. We have adapted several examples earlier developed within the EyesWeb platform. As we use simple network protocols for updating the variables in the communicator, in most cases the modification consisted of converting detected variables to a string, concatenating it with a prefix to meet the requirements of our protocol, and using EyesWeb’s NetSender component to send this new string value to our communicator. For instance, we used an EyesWeb example that tracks motion of human body, with our scripting applet to control an animated character in a simple HTML game.
Described ways of interaction can be particularly useful in active public interfaces, which already have started to use techniques to visually sense humans.
Speech-Based Content Selection and Playback
In this application we have used a speech recognizer (Sphinx-4, an open source speech recognition platform) to control the content-changer component and parameters of multimedia players using our scripting applet.

Basic configuration of components, and data flow in our TTS news reader with speech control example.
When the speech engine recognizes a phrase, it updates the registered variable in the communicator. This event also triggers a transformation that maps the speech variable into command variables for the scripting applet and/or content changer (for example phrases 'reload', 'previous' and 'next' are used to control the content changer, while phrases 'play', 'stop', 'quiet' and 'loader' are used to control the playback and volume in multimedia players such as RealPlayer).
We also enabled the dynamic reconfiguration of the speech recognizer with data from the communicator. To increase the overall performance of the player adaptation, the speech recognizer is configured to recognize a limited set of phrases. The speech recognizer receives the grammar of phrases that can be recognized, and then reconfigures to recognize these phrases. The speech recognizer can also receive a link to files with training data of the user loaded from the user profile.
TTS News Reader with Speech Control
This example combines an RSS reader, with a text-to-speech (TTS) engine, and the speech recognizer (Figure 7). The RSS reader component is based on ROME open-source syndication library [20], while the TTS engine uses FreeTTS open source library [9]. We used the same speech recognizer as in the previous example.

Basic configuration of components, and data flow in our TTS news reader with speech control example.
The RSS reader is configured so that it loads RSS feed in the communicator variable as soon as the TTS engine is ready (after it has started, or when it has finished reading previous text). The TTS engine is configured to read the text from the same variable that the RSS reader updates. In this way, both components are configured to trigger each other. We have also used the ConceptNet service to extract basic concepts and to guess the mood of RSS feeds [12]. ConceptNet is a freely available commonsense knowledgebase and natural-language-processing toolkit, which can be run as XML-RPC server. Data derived in the ConceptNet server is put in several communicator variables, and used by other modules, for example by our search engine pages which are triggered by these values, so that a user can further explore context of the news using engines such as Google or Wikipedia. Finally, the RSS reader can receive commands from the speech recognizer, so that a user can request news again, skip to news, and jump to some news item.
MOVE.ME: Content and Environment Adaptation Based on Biometric Data
The move.me prototype is ongoing research in an interactive environment in which several users can manipulate the audio-visual content presented on screens through interaction with sensor-enhanced objects, in our case cushions. The sensors embedded in these objects include pressure, galvanic skin response (GSR), movement patterns, and presence (RFID reader). Moreover, each object can be equipped with output devices, such as fans, vibrators or light-emissive fibers. The cushions within the environment are provided with different sets of sensors and output devices. A simple pressure-based cushion looks like the one portrayed in Figure 8. In order to support interaction with these types of devices in a home entertainment environment, we have been developing a system that detects the user’s current excitement state and compares the retrieved sensor data with established excitement thresholds in the user model. Based on the outcome of this comparison the system adapts the presentation of the content the user is currently involved in or it alters the environment if required. For example, the system might change presentation attributes such as font size or volume due to decreasing excitement values.

A pressure-sensor cushion, where the pressure pad is located in the center grey area.
To support the interaction with such sensor-enhanced devices we have developed several components on top of the communicator, including:
· The Device manager, is a complex sensing module which instantiates the device drivers for one or more cushions and runs the interpretation engine for each of the sensors. This module updates the variables in the communicator based on the values interpreted from the cushion’s sensors, and receives the variables transferring them into the sensors’ commands, such as activating the cushion’s light or vibrator to communicate with the user.
· The Context manager updates the current status of users and devices present in the environment. For example it tracks the spatial and interaction relation between cushions and users, based on RFID tags and change of sensor data.
· The Adaptation engine collects information from the context and device managers to draw inferences on the current state changes of a user. Based on established thresholds it determines the appropriate adaptation method and provides the communicator with instructions about the source to be adapted and the means of adaptation.
Each of the managers generates data structures that might be potentially relevant for other system components. The basic configuration and the data flow is described in Figure 9. This basic configuration has been used in several settings, with additional modules. For example, in one of the settings we use data from these managers to control the dynamic of interactive video in the VeeJay system [23].

Basic configuration of components in content and environment adaptation based on biometric data.
The communicator provides the flexibility and easy reconfigurability to facilitate such a data exchange. It proved useful during the preparation phase of several workshops where we evaluate the usability of sensor-sets for a cushion in different environment settings. We apply the same fast development cycles in the preparation of the final installation, which needs to be set up by autumn of 2006.